

In the previous Part 1, we explored the potential of Chain of Thought (CoT) prompts, resulting in a chatbot capable of answering general knowledge questions. Now, we'll enhance Pico Jarvis by integrating an external weather API service.
In this article, we delve into extending Pico Jarvis's capabilities by incorporating a weather API service. This enhancement allows Pico Jarvis to address queries related to weather conditions, temperature, and more.
To begin, let's revisit the LLM API integration from llama.cpp's server. Assuming LLAMA_API_URL is set properly, e.g. localhost:8080, calling the API is as straightforward as making a POST request with the following JavaScript snippet:
async function llama(prompt) { const method = 'POST'; const headers = { 'Content-Type': 'application/json' }; const body = JSON.stringify({ prompt: prompt, temperature: 0, stop: ["Llama:", "User:"] }); const request = { method, headers, body }; const response = await fetch(LLAMA_API_URL, request); const data = await response.json(); const { content } = data; return content.trim();}
Weather API
First, let’s pick a simple yet practical weather API, OpenWeatherMap. Visit the website, register for an account, create a fresh API key, and store it in the environment variable OPENWEATHERMAP_API_KEY. The following JavaScript snippet fetches weather information in just a dozen lines of code:
async function weather(location) { const { latitude, longitude } = await geocode(location); const url = `https://api.openweathermap.org/data/2.5/weather?units=metric&lat=${latitude}&lon=${longitude}&appid=${OPENWEATHERMAP_API_KEY}` const response = await fetch(url); const data = await response.json(); const { name, weather, main } = data; const { description } = weather[0]; const { temp, humidity } = main; return { description, temp, humidity };}
However, OpenWeatherMap requires geocoordinates, latitude and longitude. What if you only have the name of the location, e.g., “New York”, “Palo Alto”, etc.? To overcome this, we employ another service to resolve any location to its geocoordinates:
async function geocode(location) { const url = `https://geocoding-api.open-meteo.com/v1/search?name=${location}&count=1&format=json` const response = await fetch(url); const { results } = await response.json(); return results.pop();}
By combining the capabilities of both functions, you can now retrieve current weather conditions, temperature, and humidity for any given location. Let’s integrate this with the LLM.
ReAct: Reason and Act
At this stage, if you ask Pico Jarvis point-blank, “How is the temperature in <your favorite city>?”, chances are, the response might sound sensible, but its accuracy could be questionable. How can we teach Pico Jarvis to retrieve weather information and handle queries related to temperature and similar topics?
It turns out, once we established the above Chain of Thought (CoT) prompt, nudging it to think about getting an actual weather condition is not that difficult. Note that in this case, the back-end is still the one who is actually invoking the HTTP call, not the LLM itself. In this approach, the back-end orchestrates two distinct conversations with the LLM. This is something called the Reason-Act pattern, often shortened as ReAct (nothing to do with the front-end/web framework), as outlined in the paper titled "ReAct: Synergizing Reasoning and Acting in Language Models." The first conversation involves asking the LLM about its thought process on querying weather data. Subsequently, the back-end executes the actual API call to fetch the weather information. The second conversation picks up where the first left off, with the LLM continuing its thought process based on the accurate weather data obtained from the API call.
To visualize this process, here's an illustrated flow diagram:
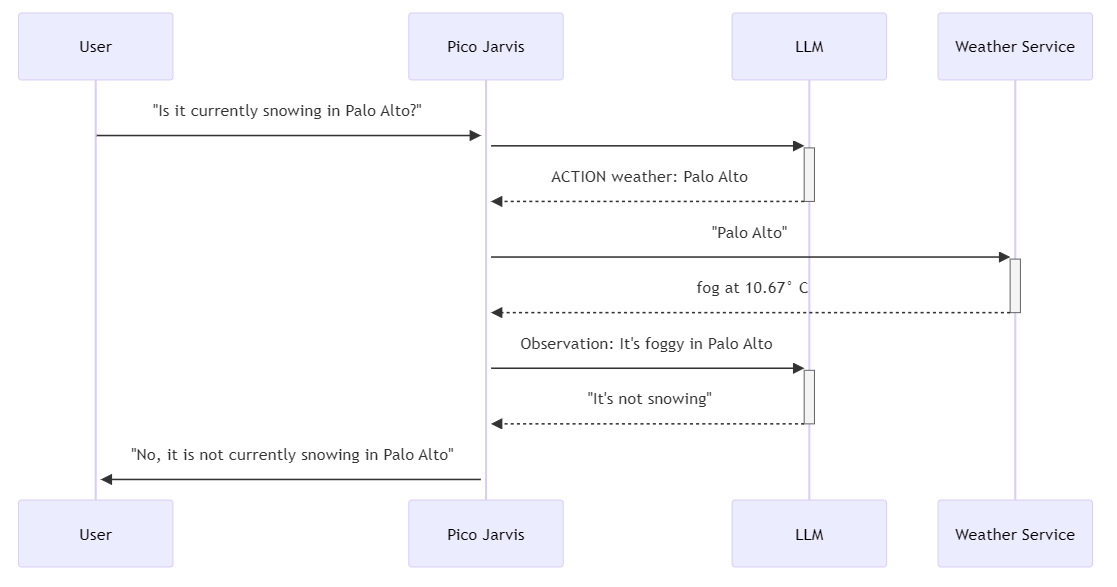
The accompanying prompt guides the LLM through a structured process of Question, Thought, Action, and Observation. An example session showcases the step-by-step interaction, demonstrating how the LLM reasons through a weather-related query and produces a final answer.
You run in a process of Question, Thought, Action, Observation.
Use Thought to describe your thoughts about the question you have been asked.
Observation will be the result of running those actions.
If you can not answer the question from your memory, use Action to run one of these actions available to you:
- weather: location
- lookup: terms
Finally at the end, state the Answer.
Here are some sample sessions.
Question: How's the temperature in Berlin?
Thought: This is related to weather and I always use weather action.
Action: weather: Berlin
Observation: Cloudy at 17 degrees Celcius.
Answer: 17 degrees Celcius.
To experience this combo of reason & act, check out this specific branch:
git checkout step-6-reasonnode pico-jarvis
If you enquire Pico Jarvis with “How’s the temperature right now in Palo Alto?”, here is the capture of the first conversation:
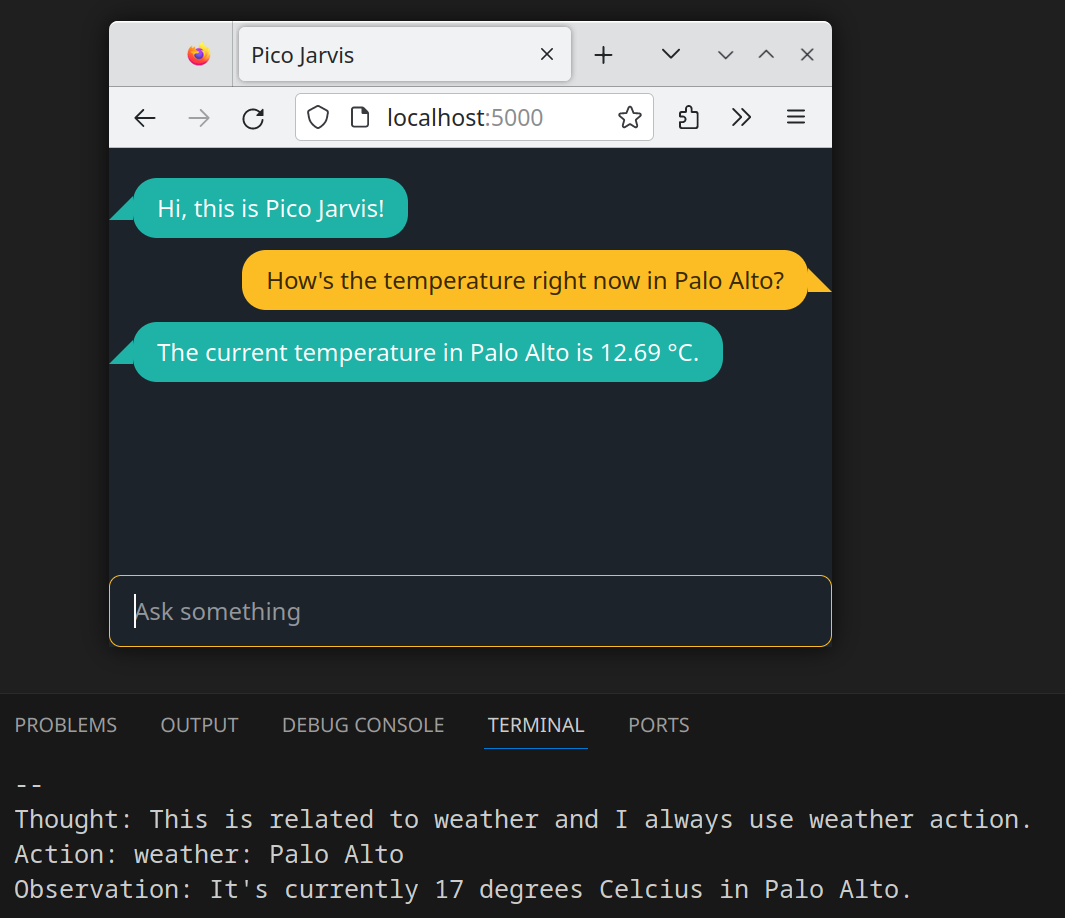
The response from LLM has all the reasoning elements: thought, action, and observation.
Thought: This is related to weather and I always use weather action.
Action: weather: Palo Alto
Observation: It's currently 17 degrees Celcius in Palo Alto.
Since this is just the first conversation, the back-end only cares about the thought process up to the Action part. The Observation part and anything after that are thrown away, rightfully so since this is just some creative writing from the LLM and not the true accurate weather data.
The execution is then paused right there, while the back-end performs an HTTP call to OpenWeatherMap API, as explained earlier, to obtain the actual weather data for “Palo Alto”, this is the location extracted from the weather: Palo Alto in the Action part.
The second conversation involves the back-end stitching together a prompt based on the obtained weather data. This prompt guides the LLM to provide an accurate answer to the original query.
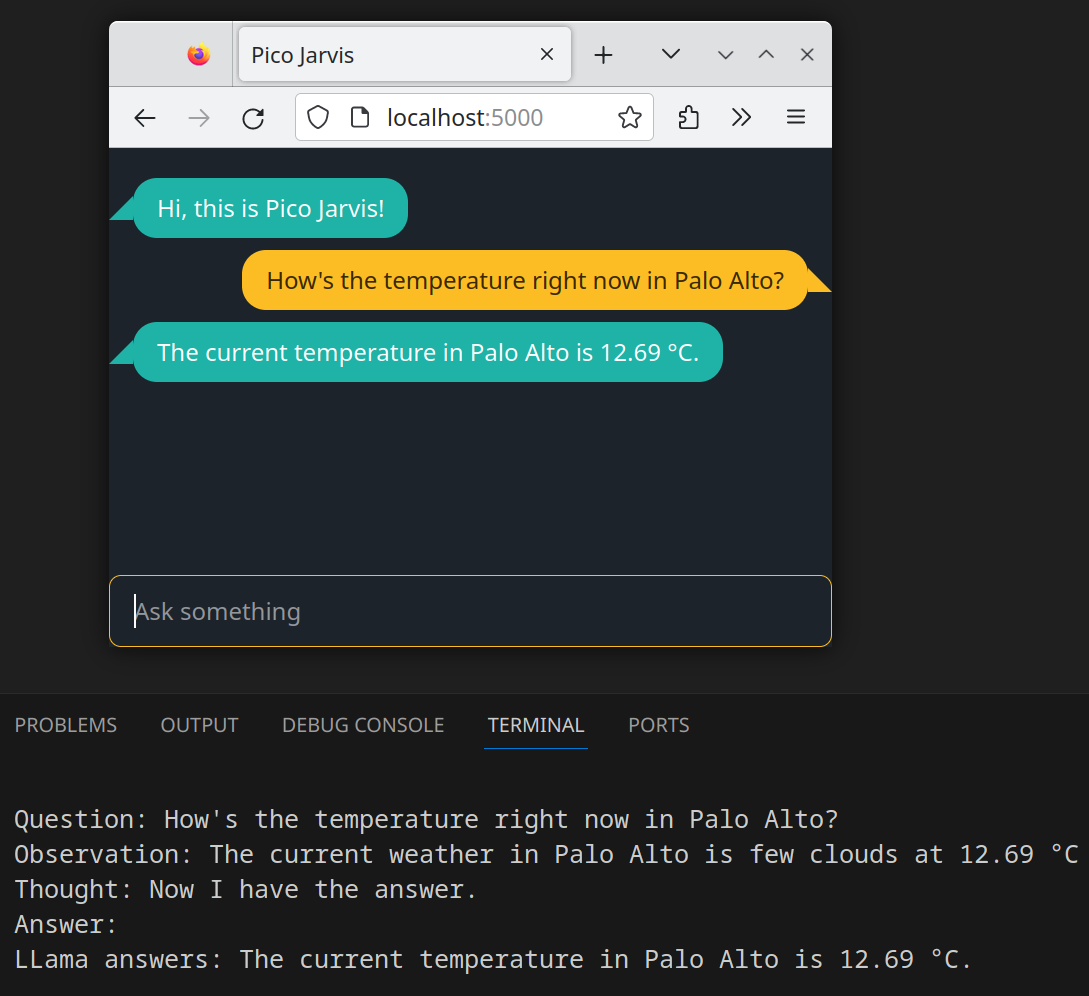
Question: How's the temperature right now in Palo Alto?
Observation: The current weather in Palo Alto is few clouds at 12.69 °C.
Thought: Now I have the answer.Answer: The current temperature in Palo Alto is 12.69 °C.
Notably, the LLM operates in a stateless manner, relying solely on the context provided in the prompt for accurate responses. Since the context now explicitly states the weather information (“few clouds” and the temperature of 12.69 °C), the LLM is able to extract the relevant piece (the temperature, correctly ignores other bits of information) to answer the original question. And that’s about it!
From the perspective of the user, the intricate back-and-forth conversations are invisible. It seems that the original question (“How's the temperature right now in Palo Alto?”) is addressed correctly (“12.69 °C”), creating an illusion of a direct and precise answer.
Here is another example:
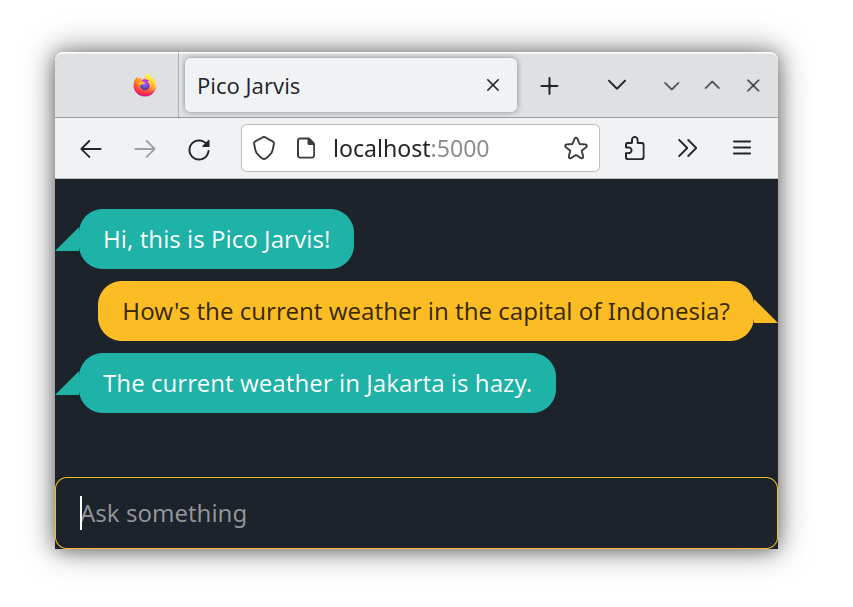
In this scenario, drawing from its training data, the LLM possesses knowledge that the capital of Indonesia is Jakarta. Consequently, Jakarta becomes the specified location in its Action segment. As in the previous instance, the back-end initiates the weather API call for Jakarta (indirectly, after getting its latitude and longitude first), retrieves the relevant data, and then returns to enable the LLM to resume and conclude the conversation. This showcases the ability to leverage pre-existing knowledge and integrate real-time data.
As you can see from this sample code, there is a lot of brittle string parsing to understand the whole Thought-Action-Observation phases. It's important to note that while the provided code focuses on clarity, a production version would require more robust handling of various error conditions and other corner cases.
Multi-turn Conversation Understanding
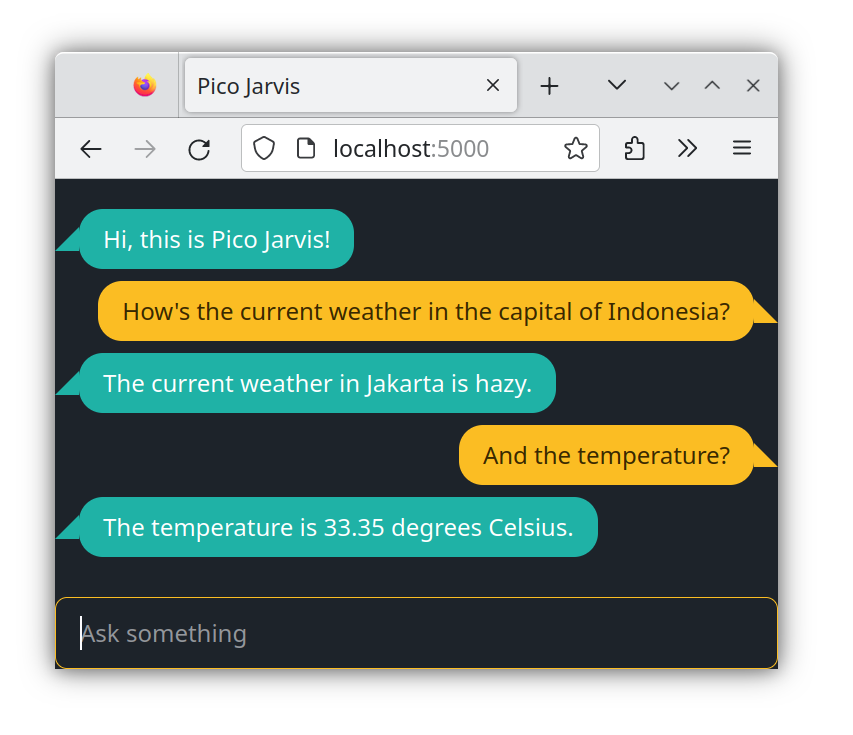
Up to this point, Pico Jarvis has treated each question as an isolated query, lacking the ability to connect them. However, we can easily change that, introducing the concept of a multi-turn conversation. Here's a glimpse of what can be achieved.
To experience this improvement, proceed to Step 7:
git checkout step-7-conversationnode pico-jarvis
In this session, the last question is internally interpreted as "What is the temperature in Jakarta?" This understanding stems from the context built throughout the conversation, even if the user doesn't explicitly mention Jakarta.
As illustrated in Part 1 with the director's script analogy, the script should encompass more than just the latest question; it should include relevant portions. In this example, we adopt a straightforward approach: inserting the last three questions and answers into the script, tracked by the back-end. The perceived script by the LLM, facilitating context comprehension, looks something like this:
This is a conversation between User and Llama, a friendly chatbot.Llama is helpful, kind, honest, good at writing, and never fails to answer any requests immediately, with precision, and concisely in 40 words or less.
User: How’s the current weather in the capital of Indonesia?
Llama: The current weather in Jakarta is hazy.
User: And the temperature?
Llama:
Following this, the LLM generates the Action to fetch weather data using the Reason-Act pattern, as described earlier. Multi-turn conversations significantly enhance the user experience, creating a smoother and more interactive interaction.
In the upcoming installment, Pico Jarvis will elevate its knowledge by integrating information from an external PDF document, enabling it to answer a broader range of questions beyond its existing memory.
Stay tuned for Part 3!