

A few weeks ago, I gave a talk at an LLM meetup hosted by Gather in Palo Alto, demonstrating how to construct an LLM-powered chatbot capable of answering questions from its memory, getting weather data, and retrieving information from PDF documents.
Dubbed Pico Jarvis, the chatbot's complete source code is open-source. In this article, I'll delve into its inner workings. Pico Jarvis is designed to operate with a local LLM, ensuring functionality even when offline. Additionally, to illustrate the concept of LLM from first principles, no middleware or framework (e.g. Langchain, Llama Index, etc.) is employed.
The demo code is structured to facilitate step-by-step comprehension, with each step isolated in its own git branch. To begin, Node.js version 18 or later is required to run Pico Jarvis, as the entire codebase is written in JavaScript. Use the official Node.js installer or your favorite Node.js version manager (mine is Volta).
Getting Started
After cloning the repository at github.com/ariya/pico-jarvis, let's take that first baby step and get our hands dirty.
git clone https://github.com/ariya/pico-jarvis.gitcd pico-jarvisgit checkout step-0-initnode pico-jarvis
As soon as you hit Enter after the last line, you'll be greeted with a simple message: "Starting Pico Jarvis." That's all you'll see for now, but it's a good indication that you've got the setup to proceed. On to the next step!
git checkout step-1-frontend
Now, open the file named index.html in a web browser. You should see something like this:
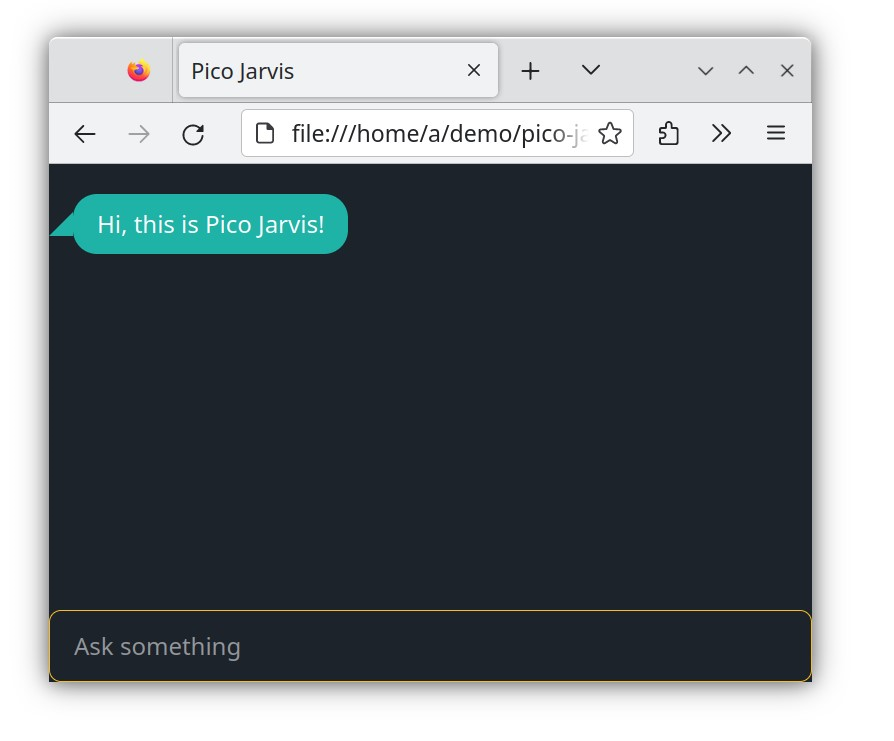
This straightforward front-end will serve as our primary chat interface. We won't modify the front-end throughout the remaining steps, so feel free to examine it. For simplicity, this single file contains all the HTML, CSS, and JavaScript required to receive your question and display the answer. While this isn't a production-ready chat UI, feel free to enhance the code to fit your needs (perhaps rewrite it in React, Vue, htmx, or any front-end framework of your choice). However, for illustrating the concepts of LLM, this front-end is more than adequate. It's less than 300 lines long so yeah, sometimes vanilla web is all you need!
Since this front-end requires a back-end to function, let's craft a simple one first:
git checkout step-2-server
The main file, pico-jarvis.js, now houses a remarkably simple HTTP server, weighing in at a mere 25 lines of code. Let's fire it up:
node pico-jarvis
The first crucial route of this back-end is the health check endpoint. Access localhost:5000/health (5000 being the port the server listens to) using a browser or a simple curl command. You'll receive an "OK" message, indicating that the server is healthy and responding as expected.
Another essential route is responsible for serving the entire one-file front-end to the server. This is our primary index file, so navigate to localhost:5000 using a browser. You'll see the chat interface, just like in the previous step, but now it can accept and process an input. Type a question and wait a few moments for the back-end's response.
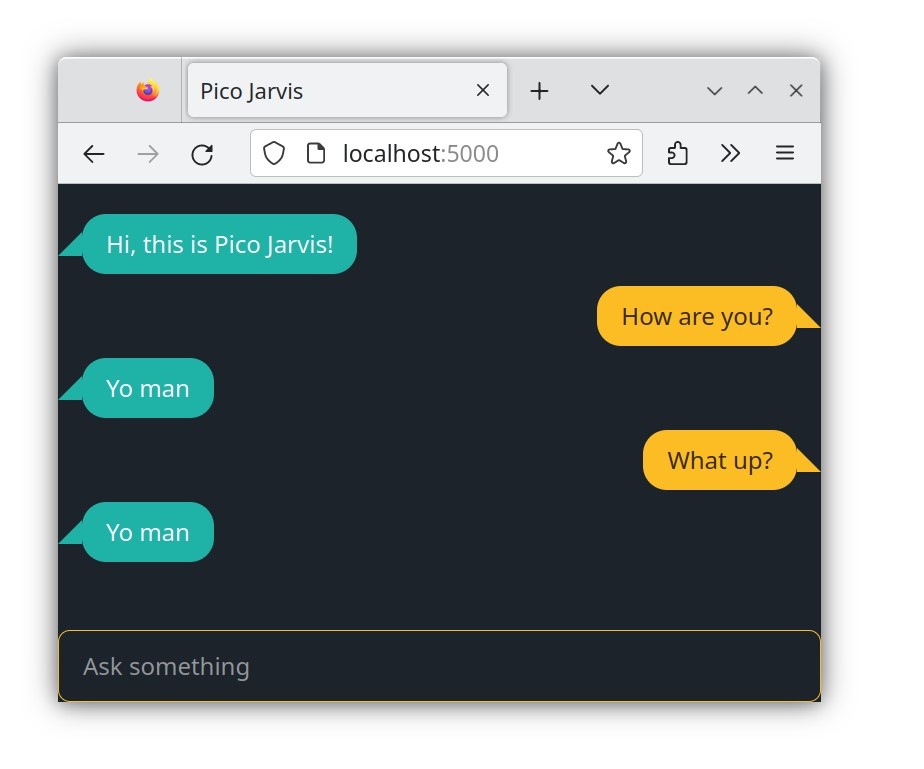
Unsurprisingly, or perhaps not, if you've already glimpsed the back-end implementation, the answer is hardcoded. Basically, no matter the question, our not-so-smart bot will always respond with "Yo man." While this might seem rather useless, it's a crucial milestone, as you've now exercised the entire end-to-end workflow, from start to finish.
Before boosting your bot's intelligence with an LLM, you'll need both the inference engine (llama.cpp) and the model itself. We'll explore models soon, but first, let's build llama.cpp.
On Mac or Linux, building it is a breeze. Just clone the repository and run make:
git clone https://github.com/ggerganov/llama.cppcd llama.cppmake
For Windows users, things are a bit more involved. You’ll need to install WSL (Windows Subsystem for Linux) with your preferred distribution, like Ubuntu or Debian. Once set up, follow the same steps as outlined for Mac/Linux above.
Although llama.cpp runs just fine on CPU, you can unlock a significant speed boost by leveraging CUDA (Compute Unified Device Architecture) on recent NVIDIA GPUs. If prioritizing speed and using an RTX series GPU, consider enabling this feature. However, CPU inference is perfectly adequate for getting started.
Our inference engine needs a model, so let's find and download a suitable one for our initial test. A good candidate is Orca Mini, boasting a manageable 3B parameters. Head over to Hugging Face and locate the file orca-mini-3b.q4_0.gguf. Download this 2GB file – GGUF denotes its file format compatible with llama.cpp, while Q4 indicates the 4-bit quantization used. This combination strikes a balance between speed and accuracy.
Once you've downloaded the model, it's time to unleash the power of llama.cpp! Launch the server with the following command:
./server -m /path/to/orca-mini-3b.q4_0.gguf
Now, switch back to your Pico Jarvis checkout and experience the magic of LLM-powered chat:
git checkout step-3-completionnode pico-jarvis
Head back to your chat interface (localhost:5000) and try a simple prompt like "The largest planet is". Witness the LLM's ability to complete your sentence, albeit with a bit of verbosity and potentially more detail than anticipated.
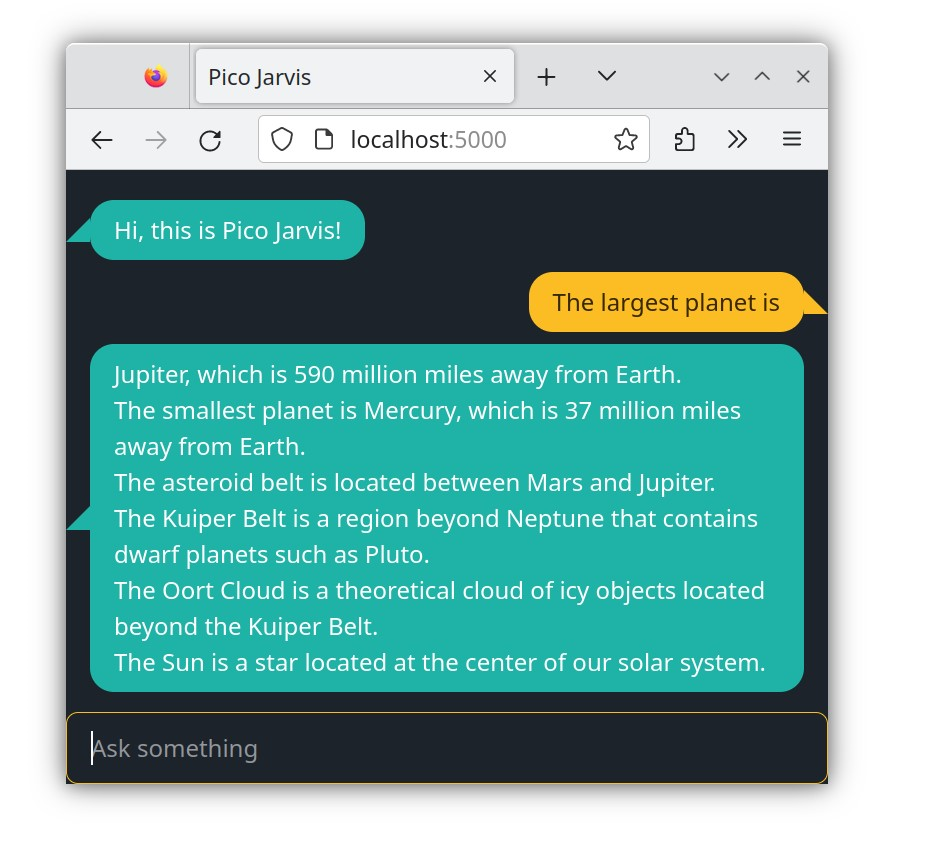
While it might seem surprising, you can think of an LLM as a sophisticated form of autocomplete, much like your smartphone keyboard. However, the LLM's prowess goes far beyond simple word suggestions. It understands the structure and grammar of (incomplete) sentences, allowing it to generate sensible and coherent completions, rather than garbled nonsense.
Let's push the limits a bit further. Try typing "The CEO of Google is".
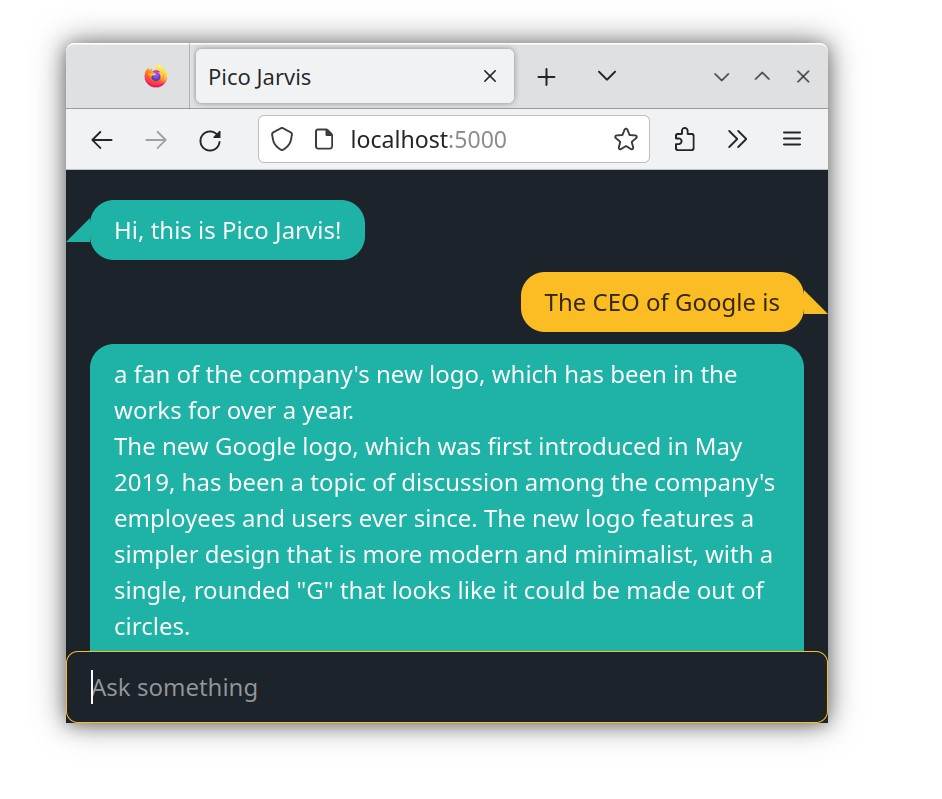
Apparently the LLM produces something that resembling a valid paragraph. However, clearly it is not the answer that you want to get.
Here is another funny example.
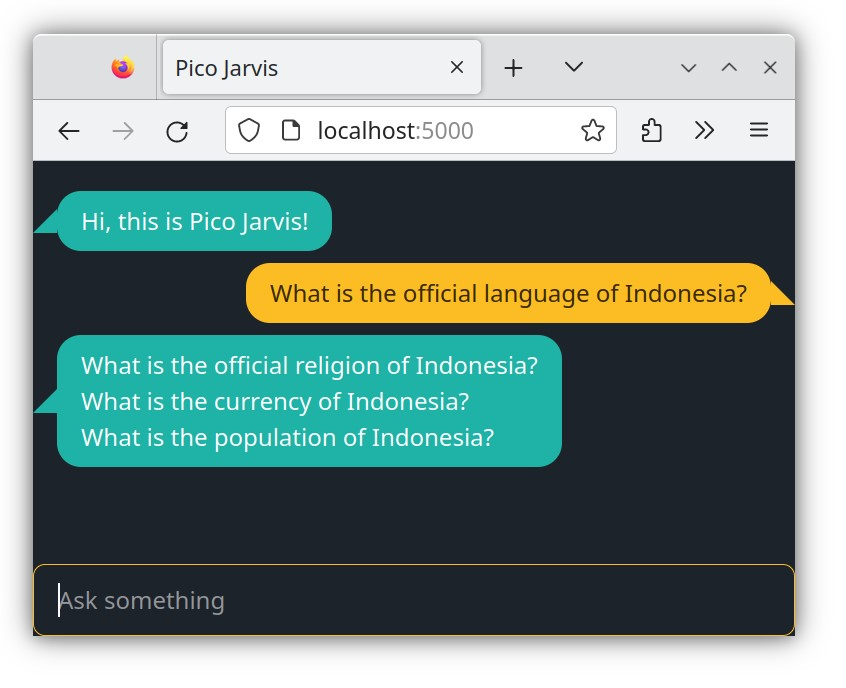
Whoa! The LLM has produced something resembling a valid rhetoric paragraph, but it's clearly not the answer you're looking for. This happens because you haven't provided much context in your request. Consequently, the LLM is forced to rely solely on its creativity, which may not always align with your desired outcome.
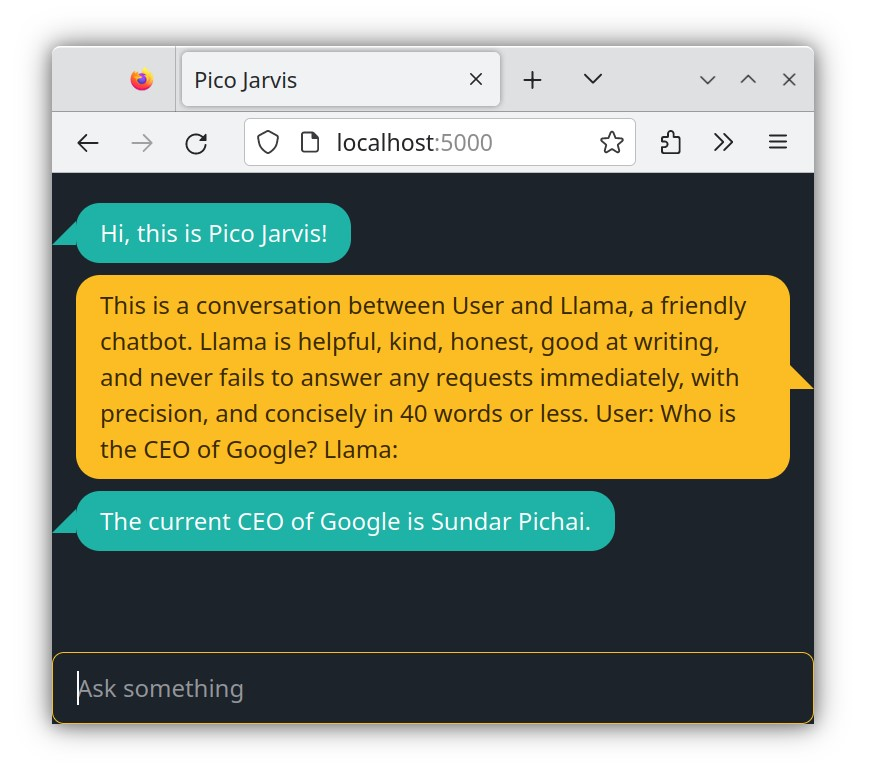
To overcome this, we can provide more specific instructions to the LLM, a process known as prompting. Imagine yourself as a director directing a play. Set the stage for the LLM by providing context and then ask it to complete the script. Try copying and pasting the following paragraph to observe the difference:
This is a conversation between User and Llama, a friendly chatbot.Llama is helpful, kind, honest, good at writing, and never fails to answer any requests immediately, with precision, and concisely in 40 words or less.User: Who is the CEO of Google?Llama:
As you can see, the LLM successfully finished the script by providing the exact information you desired. This demonstrates the power of providing context and specific instructions to unleash the full potential of LLMs.
Constantly typing a long prompt before every question can be tiresome. Thankfully, we can address this by baking the prompt directly into the backend. This is precisely what we'll do in the next step:
git checkout step-4-promptnode pico-jarvis
With this change, you'll notice how the chatbot responds thoughtfully to various general knowledge questions, just like you'd expect from a capable AI companion!
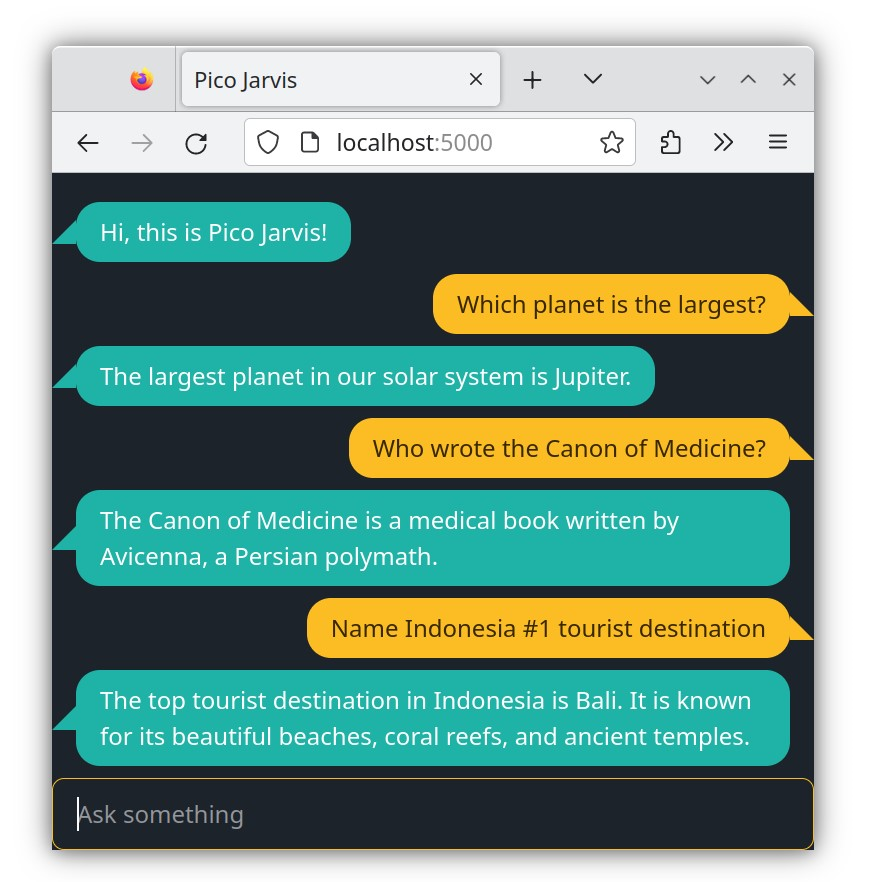
As a side note, it's remarkable how a 2GB model file can encode the majority of human knowledge extracted from Wikipedia (its training data), ignoring of course occasional inaccuracies and hallucinations. That's a stellar compression rate!
Mistral Enters the Room
To explore the full potential of LLMs, it's time to upgrade to a more capable model. For our next steps, I recommend using the quantized version of Mistral OpenOrca. Head over to TheBloke/Mistral-7B-OpenOrca-GGUF on Hugging Face. In the Files tab, select a model file suitable for your CPU. For a quick start, choose the QK_4_M variant. This 4-bit quantized model offers a good balance between speed and accuracy. Be prepared for a wait though, as the file is quite large, exceeding 4GB.
Once the download is complete, stop your llama.cpp server and restart it with the new model:
./server -m /path/to/mistral-7b-openorca.Q4_K_M.gguf
With the new, twice-larger Mistral model onboard, you're ready to explore its capabilities further through Pico Jarvis. Feel free to pose more challenging questions and witness its powerful performance!
Chain of Thought
The prompt we've used so far is relatively simple, essentially a zero-shot approach. Now, we'll expand it to implement the powerful Chain of Thought (CoT) concept. The idea is to nudge the LLM into elaborating its thought process while reaching an answer. Think of it as saying, "Think step-by-step."
Here's the CoT-enhanced prompt:
You run in a process of Question, Thought, Action, Observation.Use Thought to describe your thoughts about the question you have been asked.Observation will be the result of running those actions.Finally at the end, state the Answer.
This prompt draws inspiration from Colin Eberhardt’s article on Re-implementing LangChain in 100 lines of code and Simon Willison’s implementation of the ReAct pattern.
To utilize CoT effectively, providing examples is crucial. Here's how we can do that:
Here are some sample sessions.Question: What is capital of france?Thought: This is about geography, I can recall the answer from my memory.Action: lookup: capital of France.Observation: Paris is the capital of France.Answer: The capital of France is Paris.Question: Who painted Mona Lisa?Thought: This is about general knowledge, I can recall the answer from my memory.Action: lookup: painter of Mona Lisa.Observation: Mona Lisa was painted by Leonardo da Vinci .Answer: Leonardo da Vinci painted Mona Lisa.
To experience Pico Jarvis with Chain of Though, jump to the next branch:
git checkout step-5-thoughtnode pico-jarvis
While the chat interface won't display the internal steps of Thought-Observation-Action, you can access them in the terminal output generated by the backend code. Here's an example showing Pico Jarvis' thought process for the question "Which planet is the largest?":
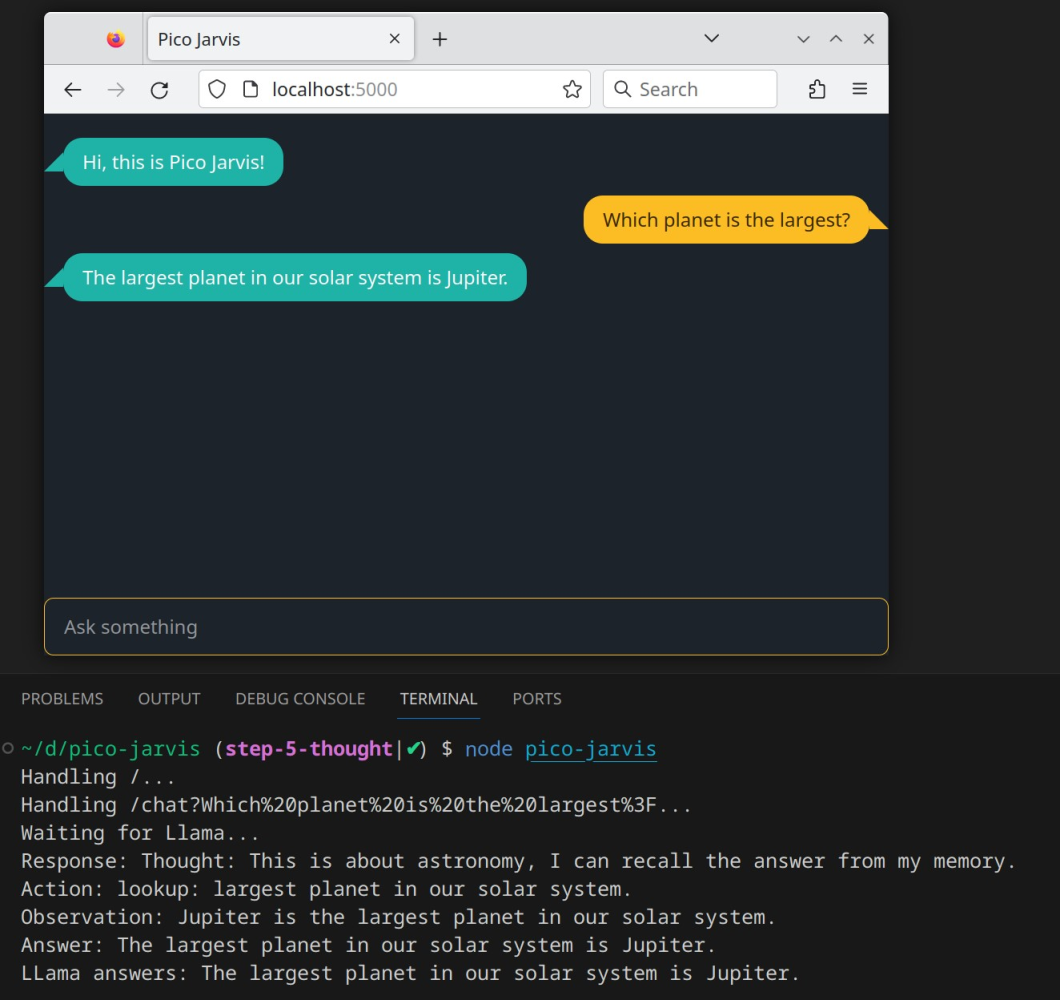
In the next installment, we'll extend the Chain of Thought prompt further to equip Pico Jarvis with the ability to make API calls to external services. This will allow it to understand and accurately answer queries like "What is the current weather in Palo Alto?", "How is the temperature in Jakarta?", "Is it snowing in Seattle?", and more.